什么是BERT
BERT是Bidirectional Encoder Representations from Transformers的缩写,中文意思大概是“双向transformer编码器表达”,“transformer”实在不知道怎么翻译了,应该是一种神经网络的深层模型。
Google在2018年已经把BERT开源了,所以谁都可以用。BERT是一种基于神经网络的自然语言处理预训练技术,其用途不仅限于搜索算法,任何人都可以把BERT用在其它问答类型的系统中。
BERT的作用简单来说就是让电脑能更好、更像人类一样地理解语言。人类在自然语言处理方面已经探索了很多年了,BERT可以说是近年最强的自然语言处理模型了。
Google在把BERT使用在搜索算法之前,就在机器阅读理解水平11项测试中获得全面超越人类的成绩,包括情绪分析、实体识别、后续词语出现预测、文字分类等等。
现在关于BERT技术的中文文章已经很多了,搜索一下会看到很多,太技术了,绝大部分我是看不懂。
什么是Google BERT算法更新
Google官方博客2019年10月25号发了一篇帖子,公布了BERT算法的一些情况。
Google自己的说法是,BERT算法在帖子发布那个星期在英文搜索中逐渐上线,然后其它语言也陆续上线。同时,BERT也使用在第0位结果(官方名称精选摘要)算法中,已经在所有语言使用。
BERT算法影响大致10%的查询词。Google认为BERT是自5年前的RankBrain之后最大的算法突破性进展,也是搜索历史上最大的突破之一。不过从过去一年的自然搜索流量看,BERT可能在搜索技术意义上的突破是挺大的,但对搜索结果和SEO其实没那么大影响。就我所接触的英文网站看,疫情和核心算法更新对很多网站的影响大多了。这里说的影响不仅仅指负面影响,也有的网站在疫情或核心算法情况下,SEO流量是大涨的。
BERT用在搜索中理解语言时的特点是:一句话不是一个词一个词按顺序处理,而是考虑一个词与句子里其它所有词之间的关系,也就是说,BERT会看一个词前面和后面的其它词,因此更深入地从完整上下文理解词义,也能更准确理解搜索查询词背后的真正意图。
从Google的描述和举例来看,“考虑一个词与句子里其它所有词之间的关系”包括了:
- 这个词前面以及后面的词
- 不仅包括前后紧邻的其它词,也包括隔开的其它词
- 词的顺序关系
- 从前往后的顺序,以及从后往前的顺序(所谓双向)
BERT解决了什么搜索问题
搜索的核心是理解语言。对用户查询词的理解是其中重要一部分,用户查询时用的词五花八门,可能有错字,可能有歧义,可能用户自己都不知道该查询什么词,搜索引擎都要先弄明白用户到底想搜索什么,才谈得到返回匹配的结果。
搜索引擎收到查询词时,根据不同情况会做很多不同处理。比如,了解基本搜索算法的SEO肯定都知道,搜索引擎会对查询词做错别字、拼写错误之类的处理,也会对查询词做同义词、近义词、异体字的扩展,这都是对查询词的简单理解处理。
情况再复杂一点,比如查询“苹果”时,搜索引擎在没有用户搜索历史的情况下,虽然大概率是在搜索手机,但无法100%确定用户到底是想搜索水果,还是手机,还是电影,还是报纸,但查询“苹果 减肥”,搜索引擎从语义分析就能知道这里的苹果指的是水果了。
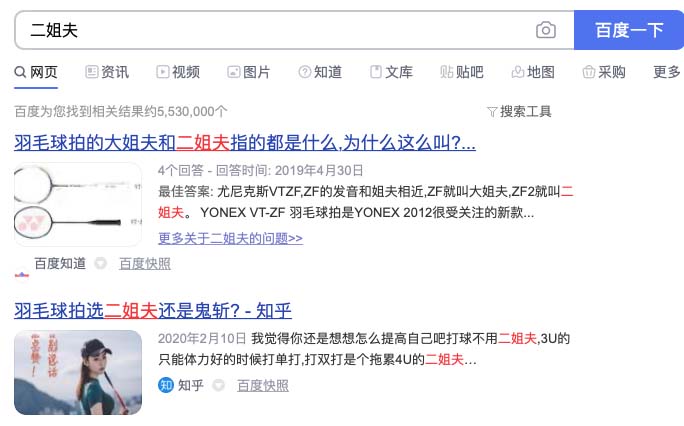
再有歧义一点,查询“二姐夫“,用户是想了解二姐她老公吗?搜索引擎很可能通过机器学习用户点击数据,早就知道用户其实是想了解羽毛球拍。Google和百度理解都没问题:
那么比如查询“新加坡 上海 机票”时,人类可以理解大概率是想找“新加坡到上海”机票,但搜索引擎很可能无法判断到底是在找“新加坡到上海”机票,还是在找“上海到新加坡”机票,因为两个查询的词在分词后是完全一样的。语义分析也失效,都是机票、旅游相关。
这种正是BERT大显身手的时候了,如前所述,BERT会考虑上下文以及词之间的顺序,还知道从前向后和从后向前的顺序是不一样的。
对英文来说,查询有for、to之类的介词而且这些介词对查询意义有重大影响时,还有比较长的、对话形式的查询,BERT能够更好理解查询的上下文及真正意义。
由于以前搜索引擎理解力不足,搜索用户也都被迫形成了一种以关键词为主的查询习惯。但我们生活中有问题问朋友时可不是用几个关键词来问的,而是以完整问句来问的。有了BERT这种对查询词的更好理解,用户才能以更自然、更人性的方式搜索。可能就是在这个意义上, Google认为BERT是搜索技术的一大突破。
Google举了几个例子,我觉得第一个是最能说明BERT特点的:
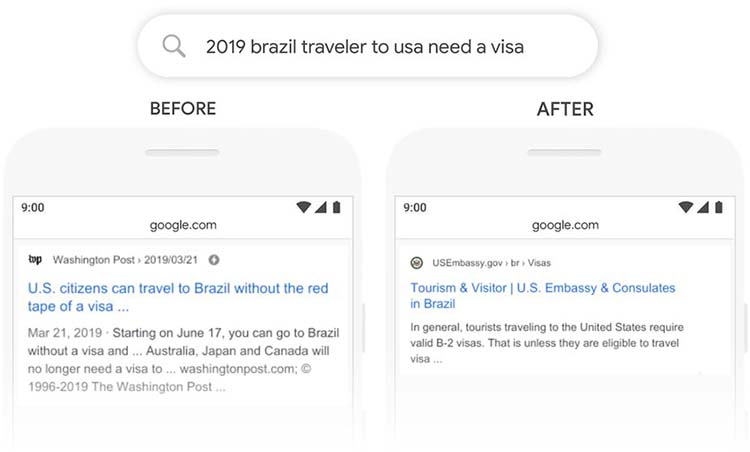
上图显示的是BERT算法上线前后的Google搜索结果,查询的词是“2019 brazil traveler to usa need a visa”(2019年巴西游客到美国需要签证)。英文里的“to”在经典的搜索算法里很可能会被当作停止词而忽略了,但在这个查询里,“to”对查询意图有决定性意义,“巴西游客到美国”与“美国游客到巴西”的签证要求是完全不同的两个意义。
使用BERT前,Google返回了美国游客去巴西不用签证的信息,使用BERT之后,Google正确判断“谁to谁”是十分重要的,返回了巴西游客到美国是否需要签证的结果。
Google给的另一个例子是查询“Can you get medicine for someone pharmacy”(在药店能给别人买药吗),介词for也经常被忽略,但这里的for要是被忽略了,意思就差远了,变成了“在药店能买药吗”。
SEO们怎么应对BERT算法
Google明确说,没有办法针对BERT做什么优化,SEO们继续为用户自然而然地写高质量文章就行了。
思考一下,觉得是有道理的,Google并没有骗我们。BERT是用于理解查询词的真正意义,是在寻找匹配的页面之前就发生的,SEO们并没有办法通过BERT使自己的内容更相关。页面内容是什么就是什么,与BERT理解查询词的过程没有什么关系。
一个反例更能说明这一点。我现在搜索“2019 brazil traveler to usa need a visa”这句话时,实际上看到的前两个结果都是错误的、美国游客到巴西是否需要签证的信息:
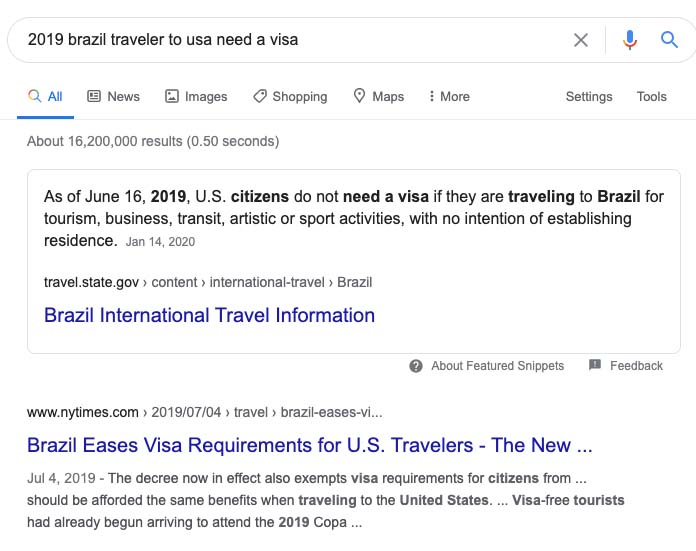
即使BERT已经上线,Google对查询的理解依然可能出问题。Google对查询词理解错误,自然返回错误的页面,和你的页面质量高不高没关系。
坚持看到这里的读者给个彩蛋。虽然没办法针对BERT进行优化,但BERT对SEO有没有别的应用场景呢?前面提过几个关键词:双向,词语的顺序,后续词语预测。实际上,BERT可以用来预测一个给定词后面可能出现的其它词。
这有什么用?比如给定一个词:SEO,BERT可以预测后面可能出现的词。那么一直预测下去,不就形成句子了?这不就是自动写作机器吗?而且是符合语义、符合语法、经过AI深度学习验证的。
已经有这类工具了,只是质量还不太令人满意,生成的中文内容更差。不知道国内会不会有人开发出基于BERT的中文自动写作软件。作者: Zac@SEO每天一贴
版权属于: 中新虚拟主机
版权所有。转载时必须以链接形式注明作者和原始出处及本声明。